遮挡剔除方法汇总
预计算遮挡剔除(Precomputed Visibility Occlusion)
预计算遮挡剔除(PVS)已经是一个20多年的技术,得益于在移动端平台上所展现的综合性能,但在各种新兴的更高效灵活更精细剔除方法中仍有跻身之处。
预计算遮挡剔除是一种离线烘焙遮挡关系,并在运行时使用这些遮挡数据的技术。算法的总体流程如下:
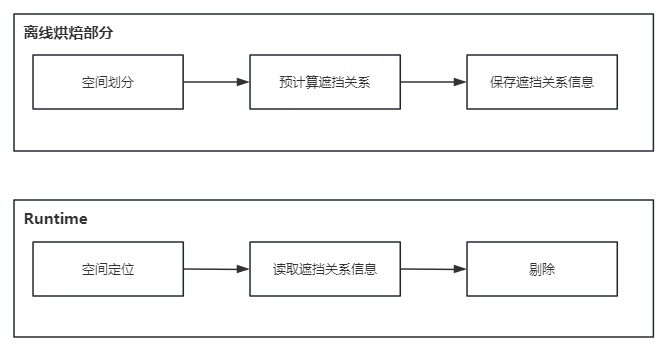
如上图所示,整个流程分为离线部分和Runtime部分。离线烘焙遮挡关系,首先进行空间划分,然后预计算遮挡关系,再把遮挡关系保存下来。在运行时只需要定位相机所在的空间位置,并使用相应的遮挡关系来设置物体是否可见即可。
空间划分指的是找到场景中相机可能达到的区域,并且将区域按照一定的规则划分成网格。这一步不是很难理解,最简单的做法就是将三维空间场景用均匀的格子进行划分。首先从俯视图进行划分,然后再在垂直维度上对高度进行均匀划分。
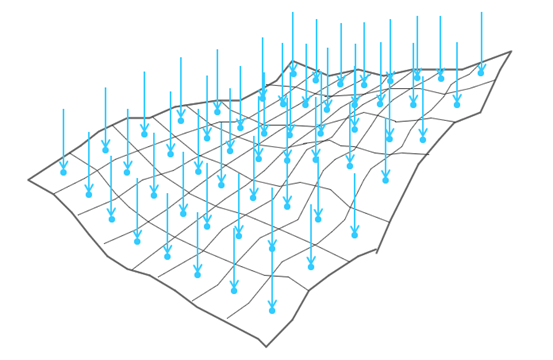
预计算遮挡关系是离线得评估一个物体是否可见,这一步是通过打射线的方式来进行评估的,具体的细节会比较多。
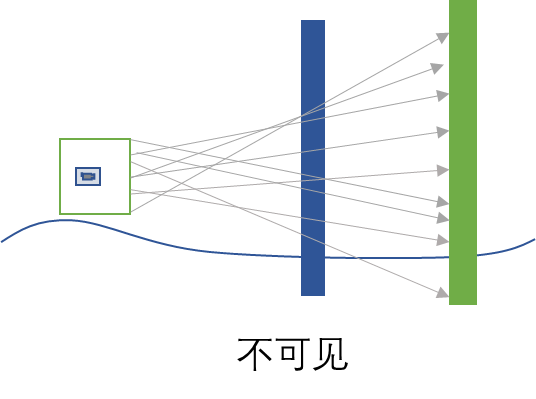
最后是将遮挡信息保存下来。对于场景中每个物体,只有可见与不可见两个选项,因此可以用BitSet来保存物体的可见性。按每个网格的可见性信息存下来,每个遮挡物用1个bit,那么数据容量会是网格数量乘以被遮挡物数量除以8。实际上如果可见性数据中存在大量的0和大量的1相连,数据压缩就有更大的发挥空间。反过来也可以启发在被遮挡物在排列序号的时候,应该尽量让聚集的模型的序号连在一起。
预计算遮挡剔除系统在运行时的消耗极小,只需要索引出来相机所在的网格,拿到网格的可见集数据,设置渲染器的开关即可完成剔除。这也是这个技术方案的一大优点,可以在手游这种资源吃紧的平台有更好的发挥空间,拿到一个还算过得去的剔除效果。
系统的扩展性还比较高,可以扩展支持流式加载、LOD、花海草海、特效渲染物件和小型的动态物件等,这种都是去做项目适配的时候需要花很多时间的地方。
而对于光线采样的优化,可以参考这篇文章中的内容,本篇文章的内容也基本是摘取自这篇文章。(跳转链接)
硬件遮挡查询(Occlusion Query)
硬件遮挡查询支持在执行绘制命令之前向GPU插入查询指令,查询指定的Draw Call中通过Depth Test的数量。
剔除的具体思路为先用一个简单的depth-only的pass将深度写入到z-buffer中,然后传入物体到GPU进行遮挡剔除,在GPU内三角形会被光栅化,其结果与z-buffer比较但不会写入深度,标记其可见像素数量n,如果n=0代表物体会被完全遮挡需要被剔除掉,反之不能剔除。最后再把信息传回CPU进行剔除。
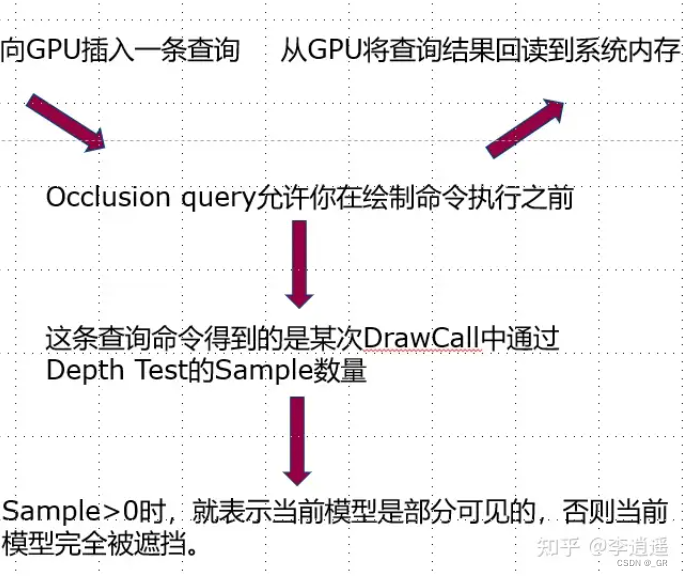
只看整个思路是完全不够的,因为DrawCall开销、VS开销以及信息回读很有可能导致剔除性能反而比不上不剔除,下面说说该方法的优化细节。
- 包围盒
对于复杂的场景哪怕只用depth only pass也有很大的VS压力,因为三角形太多了,可以通过多个紧贴的简单的包围盒或者简单的Proxy Mesh去代替高精度模型去做深度写入。同时后续做遮挡查询的时候也可以传入包围盒进行快速的查询。
- 合批
因为是depth only pass,所以不需要考虑材质,可以把多个包围盒进行batch处理减少DrawCall数量。
- 粗深度缓冲区
硬件厂商一般都会提供粗深度缓冲区来进行遮挡剔除,如z-cull和early-z等方式都会优化生成z-buffer的过程,以Tile的形式去存取深度来快速进行粗糙却保守的遮挡剔除。
- 更快的查询变体
遮挡剔除存在一些速度更快的变体,比如可以用一个bool值来表示是否至少有一个片元通过了深度测试,因为n=0则剔除,n!=0则保留,其实只有剔除和不剔除两种状态,这种变体会在发现一个片元通过了测试(n!=0)就终止后续遮挡查询了。这种方法是保守的,但是这种粗糙的测试方法封死了后面更细粒度进行剔除的路子。
- 异步回读结果

查询结果回读到CPU需要的时间非常长,如果要等GPU回读以后才进行后续流程就会造成CPU进入stall状态等待GPU,这种空转是十分浪费的,一般的策略是CPU和GPU查询异步进行,其中CPU可以向GPU发送任意数量的查询请求,然后CPU会定期检查是否有任何结果可以使用,GPU会执行每个遮挡查询,并将查询结果放入一个队列中。CPU端的队列检查非常快,同时CPU还可以继续发送查询请求或者渲染物体,而不会发生停滞。这样会导致读上一帧的遮挡剔除结果,两帧之间如果变化过大有可能出现错误遮挡。
- 支持断言/条件的遮挡查询
异步回读结果会导致CPU和GPU的延迟,CPU上传的Draw Call可能是需要被剔除的,DirectX和OpenGL都支持断言/条件(predicated/conditional)的遮挡查询,GPU会记录遮挡查询后可见物体的ID,这样哪怕CPU提交了需要被剔除的数据也不会进入后续渲染流程。
Early-Z 和 ZPrePass Culling
Early-Z指的是在片元着色器之前进行深度测试,将测试不通过的片元丢弃,减少片元着色的计算消耗。这一步一般由硬件厂商实现。

Early-Z失效
- 使用了AlphaTest(一些在片元着色器中使用clip或discard丢弃片元的操作)、AlphaBlend(ZWrite Off)
- 手动修改GPU插值得到的深度
- 关闭深度测试、关闭深度写入
ZPrePass
而ZPrePass指的其实是两个步骤。我认为应该是两个pass。使用一个pass渲染深度信息,这一步ZTest是打开的,并且ZWrite是打开的,不进行着色。然后ZTest设置为Equal,ZWrite关闭,在渲染一次,进行着色。
基于Hierarchy Z-Buffer的遮挡剔除(Hierarchy Z-Buffer Occlusion Culling)
Hierarchy Z-Buffer的遮挡剔除是利用场景渲染不透明物体时的深度值来估计物体是否被遮挡。这张深度图可以是Z-PrePass渲染所得,也可以是不透明物体渲染渲染时写入的深度图。其一般步骤如下:
构建Hierarchical Z-Buffer,对深度图进行降采样,保存“最远”深度值。
回读Hierarchical Z-Buffer并在CPU中对物体进行深度测试。
上面第二步也可以在GPU中做完再将结果回读到CPU中,再对物体进行消失和显示的操作。
在获得了Hierarchical Z-Buffer之后,只需要将每一个物体进行相同的投影,采样Hierarchical Z-Buffer中的深度与物体包围盒投影的最近Z值进行比较,一般会选取一个层次较低的层级开始比较。当物体的投影Z值比所有采样结果更远时,表明物体被完全遮蔽了,不显示。否则表明该层级的结果不准确,继续往更高层级进行采样。
构建Hierarchical Z-Buffer
这很好理解。降采样,取最远深度。如下图所示,从左往右依次降级,每2x2的像素块中取最远深度生成低级的mipmap,最后会生成到1x1大小的贴图。

然而实际上在UE的实现中,并不是按2x2的像素块进行降级,而是按16x16的像素块进行降级。笔者在实践中,按8x8的像素块进行降级生成mipmap,只需要生成4张mipmap即可获得不错的剔除效果。然后是回读Buffer并在CPU中做遮挡查询和剔除操作。
CPU中对物体进行深度测试
每个物体的深度测试是可以并行进行的,因此借助Unity的JobSystem和Burst优化,可以获得比较好的性能效果。这一步计算物体包围盒投影到屏幕上的AABB矩形,并根据矩形的最长边选取应该从哪一级的mipmap开始做深度测试,选取的公式如下:

随后便是遍历AABB矩形在该级mipmap上覆盖的像素,读取其中的深度值与物体最近的Z值进行比较。这个过程通俗的解释就是,如果物体的最近的Z值被屏幕上最远的深度遮挡了,说明物体其他位置的像素都是被遮挡的,就不需要进行更精细的比较了。
一些优化想法
在一般的实现中,如果每个物体都去做深度测试,未免有些得不偿失。可以将一些投影在屏幕上比较小的物体,做深度测试。而投影面积较大的物体,只做视锥剔除,而不做深度比较。感觉上这样会对算法速度有较大提升。
